
Классификация вещей — самая популярная задача во всём машинном обучении.
Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике.
Возьмем другой пример полезной классификации. Вот берёте вы кредит в банке. Как банку удостовериться, вернёте вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Существует множество различных алгоритмов классификации, таких как логистическая регрессия, метод опорных векторов, метод ближайших соседей, наивный байесовский классификатор, но настоящая звезда шоу — это древовидные модели. Мы подробно рассмотрим как работают алгоритм Decision Tree, как мы можем объединить деревья, чтобы создать Random Forest, и почему эти штуки так чертовски хороши в том, что они делают.

Decision Tree
Давайте рассмотрим принцип работы алгоритма решающего дерева (Decision Tree), который по-сути является строительным блоком модели случайного леса (Random Forest).
Принцип работы решающего дререва довольно интуитивно понятен. Готов поспорить, что большинство людей использовали дерево решений, сознательно или нет, в какой-то момент своей жизни.
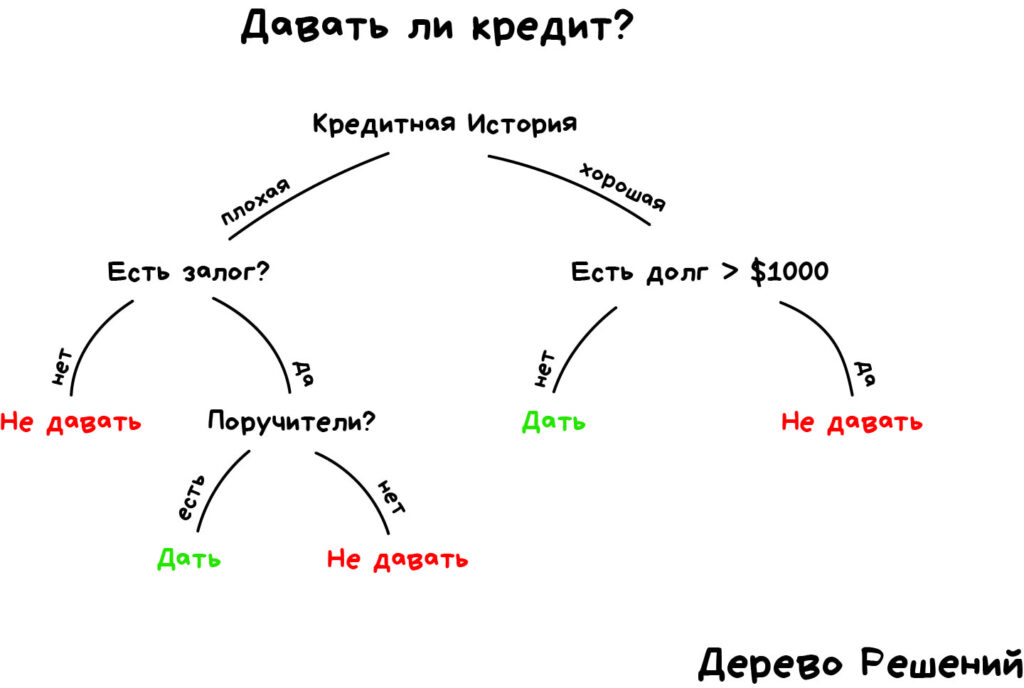
Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заёмщика больше, чем 25934 рубля?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Одно из преимуществ древовидных моделей в том, что получившиеся вопросы и ответы можно интерпретировать и исследовать причину.
Для примера с выдачей кредита банком, дерево решений может помочь банку принять решение о выдаче кредита на основе ряда признаков о заявителе. Процесс построения дерева начинается с корневого узла, где выбирается признак с условием (решающим правилом), который наиболее явно разделяет данные по целевому признаку (определяется с помощью энтропии или коэффициента Джини), пусть это будет признак «Наличие работы у заявителя».
Узел разбивается на два или более потомков (дочерние узлы) на основе значения выбранного признака. Если после разбиения узла все примеры (заемщики) в каждом дочернем узле принадлежат к одному классу, то узел становится листом — последним узлом, на котором не осуществляется разделение. Объявление узла листом также может произойти при достижении некоторого условия остановки, задаваемого пользователем (например, минимально допустимое число примеров в узле или максимальная глубина дерева).
Объект попадает в лист, только если соответствует всем правилам на пути к нему, таким образом к каждому листу есть только один путь, поэтому каждый объект может попасть только в один лист, что обеспечивает единственность решения.
Для каждого нового дочернего узла процесс повторяется, пока не будет достигнут заданный критерий остановки. Это может быть, например, достижение определенной глубины дерева.
Гиперпараметры алгоритма Decision Tree определяют как дерево строится и могут влиять на его точность и скорость. Некоторые из основных гиперпараметров, которые можно настроить, включают в себя:
-
Максимальная глубина дерева — это максимальное количество уровней в дереве. Если глубина слишком большая, дерево может переобучиться, что приведет к плохой обобщающей способности.
-
Минимальное количество объектов в листе — это минимальное количество элементов, которые должны быть в каждом листе дерева. Этот параметр позволяет избежать переобучения и улучшить обобщающую способность модели.
-
Критерий разделения — это мера, используемая для выбора признака для разделения дерева. Наиболее распространенные критерии — это энтропия и коэффициент Джини.
-
Минимальное количество элементов для разделения — это минимальное количество элементов, которые должны быть в узле, чтобы он мог быть разделен. Этот параметр помогает избежать создания узлов с малым количеством элементов.
В чистом виде деревья сегодня используют редко, но вот их ансамбли лежат в основе крупных систем и зачастую уделывают даже нейросети. Например, когда вы задаете вопрос Яндексу, именно толпа деревьев бежит ранжировать вам результаты.
Random Forest
Случайный лес, как следует из его названия, состоит из большого количества отдельных деревьев решений, которые работают как ансамбль.
Данные разделяются на выборки в зависимости от количества деревьев с помощью bootstrap. Каждое дерево обучается по алгоритму Decision Tree (на разных выборках) и выдает прогноз класса. Затем проводится голосование —каждое дерево выдвигает свое предсказание для одного объекта, в итоге выбирается то предсказание, которое дало большинство деревьев. Мы не выбираем одно конкретное дерево, которое дало наиболее правильные ответы, а усредняем результаты предсказаний всех деревьев для получения более стабильной и устойчивой модели.
Такой ансамбль, состоящий из множества моделей модели машинного обучения одного типа которые обучаются независимо друг от друга, а конечный результат определяется голосованием, называется Беггингом (Bootstrap AGGregatING).
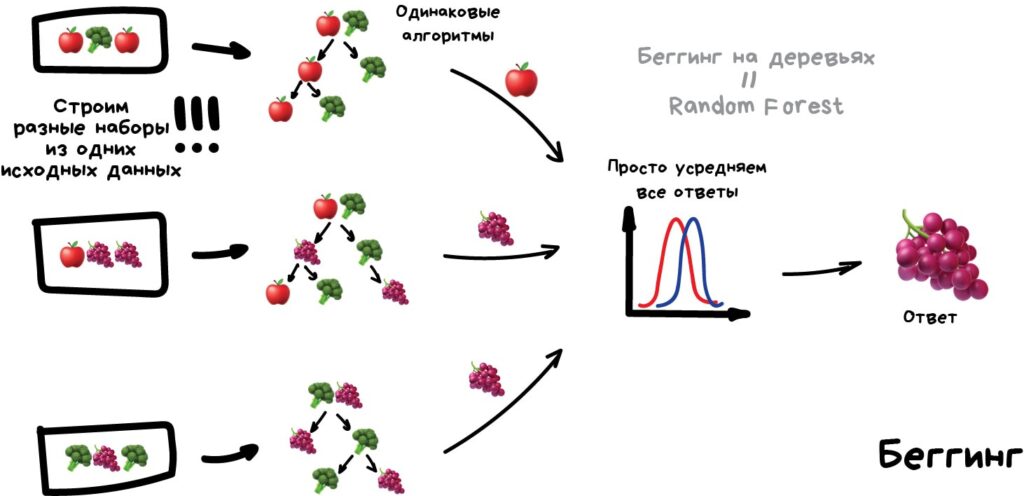
Фундаментальная концепция случайного леса проста, но мощна — мудрость толпы. Говоря языком науки о данных, причина, по которой модель случайного леса работает так хорошо, заключается в следующем:
Большое количество относительно некоррелированных моделей (деревьев), работающих как комитет, превзойдут любую из отдельных составляющих моделей.
Таким образом, Random Forest имеет множество преимуществ по сравнению с Decision Tree:
-
Устойчивость к переобучению: алгоритм Decision Tree может быть склонен к переобучению, особенно при наличии большого количества признаков. Random Forest же способен предотвратить переобучение, используя методы случайной подвыборки данных и случайного выбора признаков при каждом разбиении.
-
Лучшая точность: благодаря методу случайного выбора признаков и случайной подвыборки данных, Random Forest обычно имеет более высокую точность по сравнению с Decision Tree.
-
Может использоваться для решения задач регрессии: в отличие от Decision Tree, который может использоваться только для задач классификации, Random Forest может использоваться и для задач регрессии.
-
Может обрабатывать отсутствующие данные: Random Forest может работать с данными, содержащими отсутствующие значения (missing values), благодаря тому, что он использует только подмножество признаков при каждом разбиении.
-
Более устойчив к шуму: благодаря случайной подвыборке данных, Random Forest более устойчив к шуму в данных, что может приводить к более стабильным результатам.
Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это работа алгоритма Random Forest. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Однако, у Random Forest также есть несколько недостатков. Например, алгоритм может быть более трудоемким в вычислительном плане, так как он работает с большим количеством деревьев и требует больше вычислительных ресурсов для обучения. Кроме того, в отличие от Decision Tree, интерпретация результатов Random Forest может быть более сложной, поскольку она включает в себя несколько деревьев.
В заключении хочется подчеркнуть, что древовидные модели машинного обучения, такие как Decision Tree и Random Forest, являются мощным инструментом для решения задач классификации и регрессии. Они могут быть использованы в различных областях, включая финансы, медицину, бизнес и многие другие.
Decision Tree может быть полезен для простых задач классификации и регрессии, когда не требуется высокой точности и сложности. Этот алгоритм позволяет интерпретировать результаты, что делает его особенно полезным в областях, где важно понимание того, как принято решение.
Random Forest является более мощным алгоритмом, который может обрабатывать более сложные задачи, улучшая точность и сокращая переобучение. Он может обрабатывать большие объемы данных и является надежным выбором для задач, где важна точность.
Однако, несмотря на все преимущества, древовидные модели могут страдать от некоторых ограничений. Они могут быть склонны к переобучению на небольших наборах данных, а также могут иметь проблемы с обработкой категориальных данных.
В целом, древовидные модели машинного обучения являются ценным инструментом в арсенале дата-сайентиста. При правильном выборе алгоритма и настройке параметров, они могут обеспечить точные и интерпретируемые результаты для решения многих задач в различных областях.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}